PyTorch 入門 -Mac book proでチュートリアル-
目次
PyTorchとは
ディープラーニングフレームワークの一種です。
元々はChainerからフォークしたらしいですが、その後書き直しを行ったようです。
Yep, the PyTorch autograd codebase started with a fork from Chainer — but then rewrote it in highly optimized pure C
— James Bradbury (@jekbradbury) January 18, 2017
FacebookのAIリサーチグループが開発しています。
特徴
- Numpyに似たTensorを使ってGPUの計算力を活用する
- tape-based autograd system
最近は論文の実装がPyTorchで上がることが早いらしいです。
環境
- MacBook Pro (Retina, 15-inch, Mid 2015)
- macOS High Sierra 10.13.5
- Python 3.6.3
- PyTorch 0.4.0
2018年6月4日現在、数ヶ月中にPyTorch 1.0が出ると言われているので本記事は数ヶ月で参考にならなくなるかもしれません。詰まった場合は公式を参考にしてください。
MacOSにインストール
公式のGet Startedに自分の環境を入力してインストールコマンドを取得しましょう。
今回はMacOS、Python 3.6で行います。
CUDAはないのでNoneを選択。GPUを使った計算はできませんが一通りMac bookで動かして見ます。
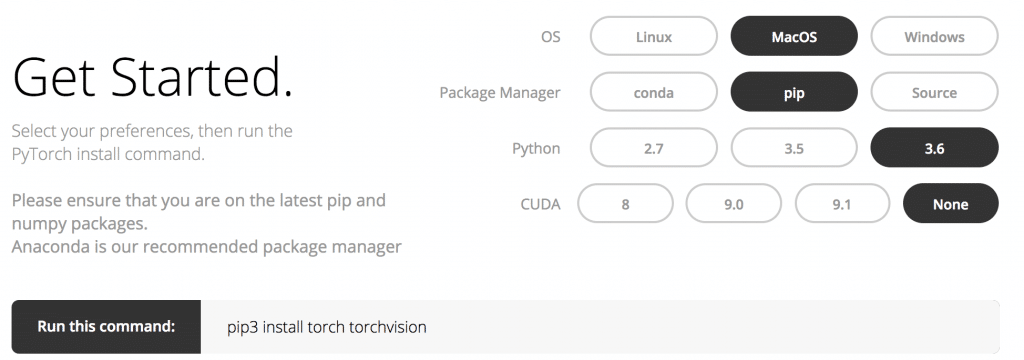
ターミナルでpip installを実行。
チュートリアルを動かしてみます。
PyTorchチュートリアル
PyTorchの公式チュートリアルは大きく3つに分かれています。
- BEGINNER TUTORIALS
- INTERMEDIATE TUTORIALS
- ADVANCED TUTORIALS
まずはBEGINNERの60 Minute Blitzから入りましょうと書いてあるので素直に従います。。
A 60 Minute Blitz
まずはWhat is PyTorch?を読みながらJupyter Notebookで基本動作の確認を行います。
なお以降のチュートリアルではそれぞれの章の最下部にPythonもしくはJupyter Notebookがダウンロードリンクが用意されているので適宜活用します。

What is PyTorch?
早速RuntimeError: Overflow when unpacking longというエラーが出ました。
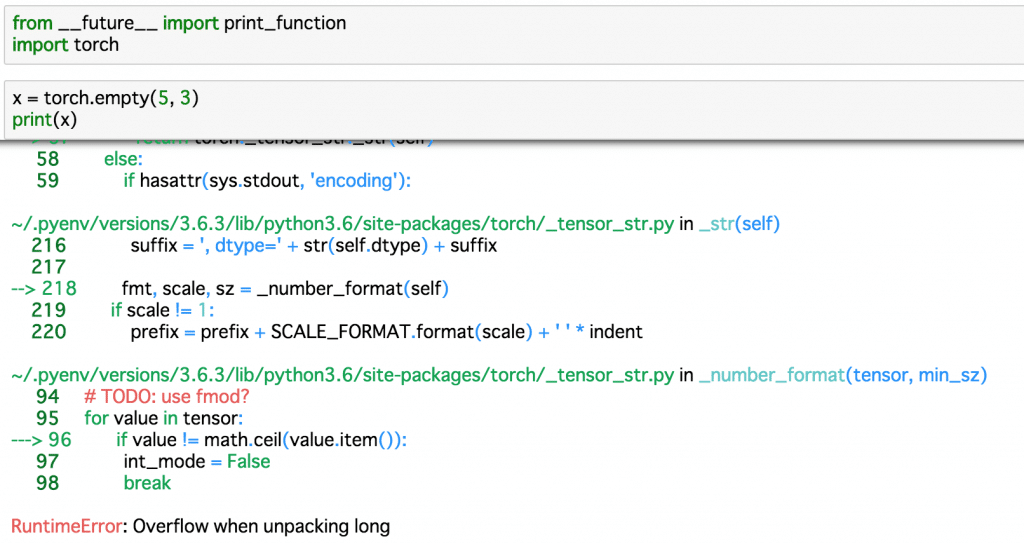
調べるとフォーラムに回答がありました。
torch.empty()はun-initializedなデータであり、これは非常に桁数の大きいfloat型であるためOverflowしてしまう、とのことです(多分)。
なのでempty()の代わりにrand()を使って動作確認をします。
ちゃんとPyTorchがインストールされているようです。
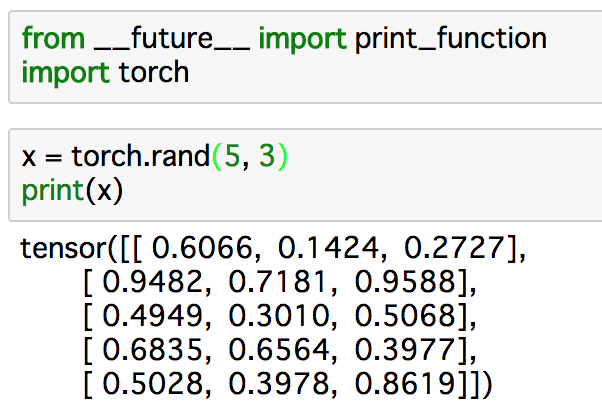
NumPyと似た使い方ですね。
その後も大体NumPyライクな操作法の紹介が続きます。
またPyTorchのTensorはnumpy()メソッドで簡単にNumPy Arrayに変えることができます。
逆にNumpy ArrayをTensorに変換するにはfrom_numpy()メソッドを使います。
あとはcuda.is_available()を使ってCUDAが使えるか確認します。
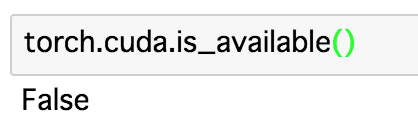
今回使っているMac book proでは使えないので想定通りですね。後ほどGPUマシーンではTrueになること確認しましょう。
余談ですが、ここで「~ is a breeze.」が「楽勝だぜ」という意味だと知りました。
Neural Networks
ここではLeNetを例にネットワーク、損失関数、誤差逆伝播、重みの更新の方法を確認します。
引用: Gradient-based Learning applied to document recognition.
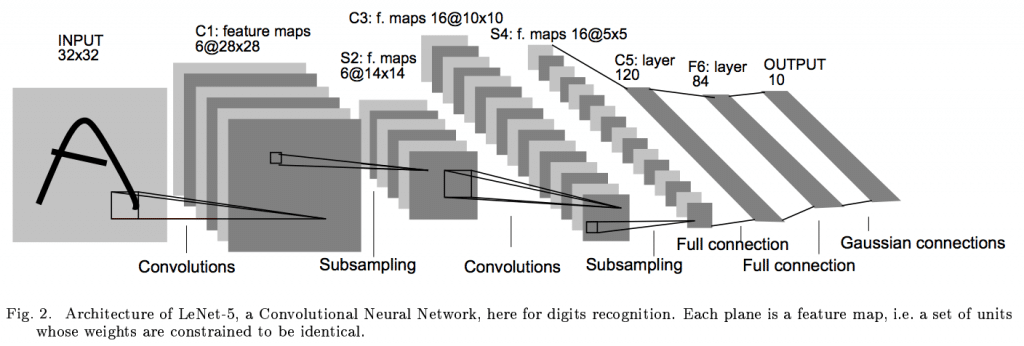
日本語訳の記事がいくつかあるのでそこら辺を参照しながら理解します。
ただし、PyTorch 0.4.0のアップデートでVariableがTensorに統合されたのでその辺りは読み替える必要があります。
重みの更新ではoptimを使うことでSGDやAdamなど使いたい手法が異なっても同様に扱うことができるようになっていたり、forward()を定義するだけでbackward()が自動的に定義されるのが便利ですね。
Training a classifier
ここではCIFAR-10というデータセットを使って画像の分類タスクを実装します。
cat、bird、shipなど10クラスの画像が1クラスにつき6000枚ずつ、合計60000万枚含まれるデータセットです。
torchvisionを使うことで簡単にデータセットを入手することができます。
ダウンロードには10分ぐらいかかるので気長に待ちます。
他に利用可能なデータセットはGithubから確認できます。定番のMNISTなんかもありますね。
ともあれ、ダウンロードをした後に画像とラベルをチェックしてみます。

前章で学んだネットワークの作り方や損失関数の定義の仕方を振り返りながら学習を回してみます。
大体55%ぐらいの精度になると思います。
MNISTを試してみる
コピペだけでは理解できないのでLeNetでMNISTを解いてみます。
勉強しながらコメントを付け加えたものをGithubにあげました。
まだ空では書けないので以下のページを参考にしながら、むしろCIFAR-10とどこが変わるかを見比べたいです。
Neural Networksのページでも書かれているようにMNISTのオリジナルの画像サイズは28×28なのでLeNetに入れるためには32×32にリサイズする必要があることを注意します。
画像のリサイズなどの処理はtransforms.Compose()でまとめて設定します。
CIFAR-10では以下のようにTensor化と正規化を行いました。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
MNISTでは以下のようにTensor化の前にリサイズを行いましょう。
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
])
あとはネットワークをいじる必要はありません。
精度は98%くらい。

結局のところtransforms.Compound()をちょっと書き換えるだけで済んだのですが、答えに至るまで紆余曲折を経て勉強になりました。
多少コメントをつけたJupyter-NotebookをGithubに上げたので参考になれば幸いです。
GPUの利用
シンプルに、ネットワークと入力データをCUDA用に変換すれば良いです。
以下のようにtorch.deviceでdeviceを取得し、to(device)でネットワークを実行環境(CPUなりGPUなり)に合わせます。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
並列処理する場合はこんな感じです。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
net = net.to(device)
GPU利用状況チェック
実際にGPUが使われていることを確認します。
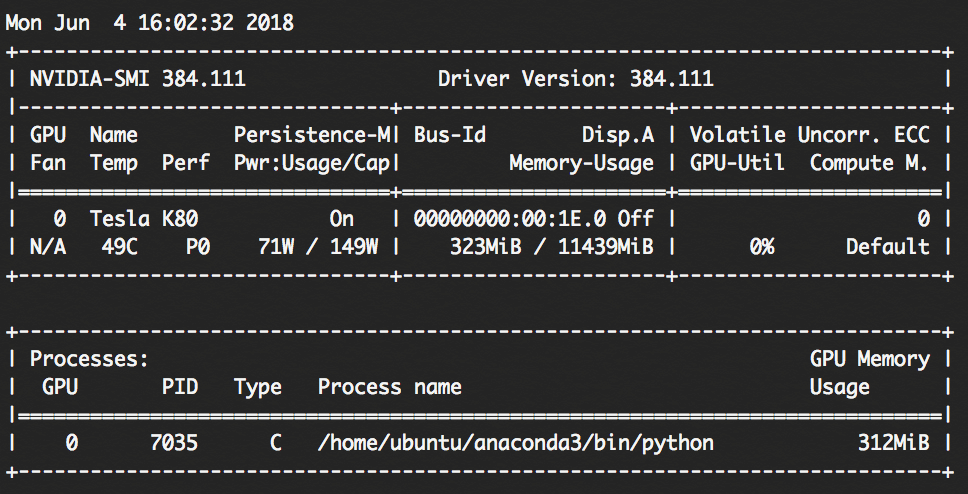
以下のコマンドでGPUの利用状況を1秒ごとにチェックすることができます。
watch -n 1 nvidia-smi
GPU-Utilが0%であることを確認します。
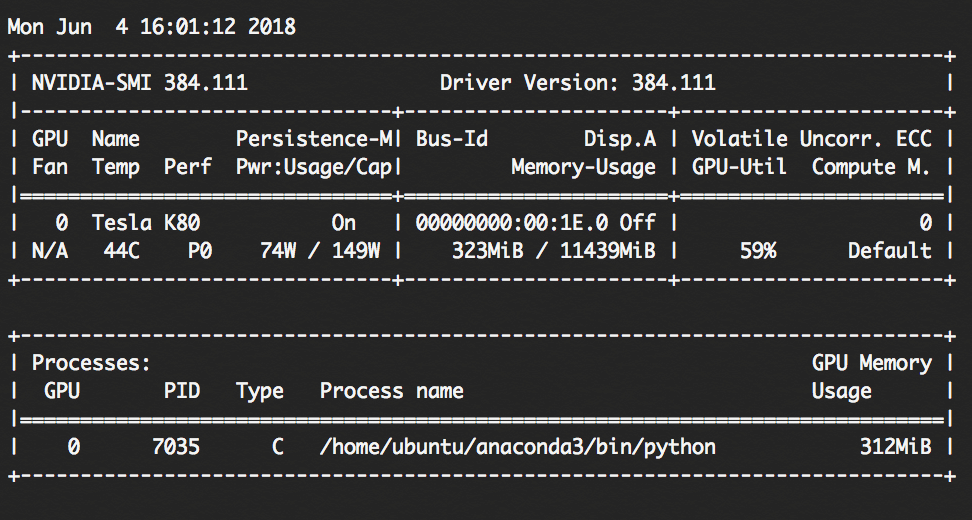
これを表示した状態で先ほどのJupyter Notebookの学習を回すと、GPU-Utilが59%になりました。
実際にGPUが使われていることが確認できました。
参考
- PyTorch
- Github | pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
- PyTorch Tutorials
- Optional: Data Parallelism – PyTorch Tutorials 0.4.0 documentation
- python 3.x – Overflow when unpacking long – Pytorch – Stack Overflow
- pytorch超入門 – Qiita
- PyTorch 初心者向けのTutorials 3/5 – Qiita
- PyTorchでMNISTをやってみる – 今日も窓辺でプログラム
- examples/main.py at master · pytorch/examples
- How to check your pytorch / keras is using the GPU? – Part 1 – Deep Learning Course Forums
