世の中の全ての化合物を取得する
こんな感じのことやってます。
友人と動物実験の条件のデータベース作成を目論んでいます。
ガンの種類、マウス近交系、薬剤、投与経路を取得できるようになりました。
画像ではC57BL/6という種類の卵巣がんマウスにガンシクロビルという薬を腹腔内投与したという内容が抜き出せました!テクノロジーで動物実験減らそう。 pic.twitter.com/Q4UgtUSJh4
— 山田涼太 (@roy29fuku) December 9, 2017
化合物の辞書が必要です。
Sigma-Aldrich(化学薬品メーカー)の商品ページから頑張ってクローリングして作成しましたが、商品名で取得されてしまうのであまりイケていませんでした。
(Insulin humanとかで辞書に追加されるので論文中のInsulinという単語を取りこぼす)
色々調べてたらアメリカ国立衛生研究所(NIH)がデータベース公開しているそうな。
その名もPubChem。
PubChemとは
NIHの中の国立生物工学情報センター(NCBI)が公開しているデータベースです。
NCBIはPubMed運営しているとこですね。
PubChemにはSubstance、Compound、BioAssayの3つのデータベースがあります。
Substance: データの提供者が化学物質について情報をアップロードするとここに溜まっていく。投稿毎にID(SID)が振られるので、同一の物質、例えばアスピリンに関するレコードがダブっていたりする。
Compound: Substanceのダブりを統合したものがCompound。一意なID(CID)が振られる。
BioAssay: 化学物質に関する生理活性試験の結果のデータベース。それぞれの試験結果はSIDと結びついている。
PubChemで対象としているのは以下のような低分子が主とのこと。
- Chemical compounds including drugs
- Nucleotides including siRNAs and miRNAs
- Carbohydrates
- Lipids
- Peptides
- Chemically-modified macromolecules
利用について
Substance、Compound、BioAssayに関してそれぞれ検索することができます。
使い方はあまり情報がないのですが、以下の動画で簡潔にまとまっています。
引用元: PubChemを利用して化学物質やアッセイの結果を調べる 2017 統合TV(togotv)|生命科学系DB・ツール使い倒し系チャンネル | DOI: 10.7875/togotv.2017.121
PubChem XMLファイルの読み方
さてダウンロードしましたが、未知の物質に関してのファイルを開いても構造が理解しにくいです。
一応、pubchem/specifications/pubchem.xsdにファイルの記述ルールが補足されていますが、
既知の物質についてのCompoundファイルを引っ張って知っている情報と照らし合わせてみます。
PubChemの検索ページを開きます。
適当にセトロニンで検索してみましょう。
心安らかでいるために必要なやつです。
足りない人は日光浴びましょう。セントジョーンズワート飲みましょう。SSRI処方してもらいましょう。
失敗①: Compoundで検索
Compoundから検索してみました。
(後述しますが失敗。時間がない方は次のSubstanceの項へ。)
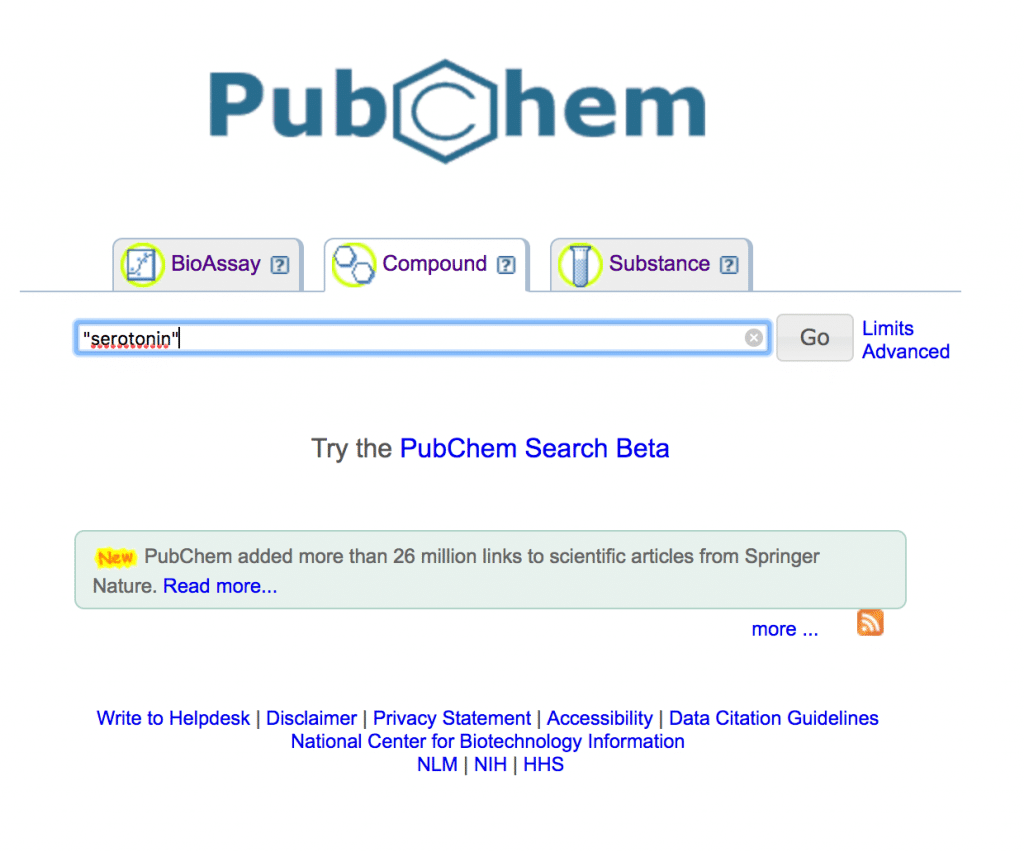
検索結果。一番上の人がセトロニン。
CIDをメモっておきます。
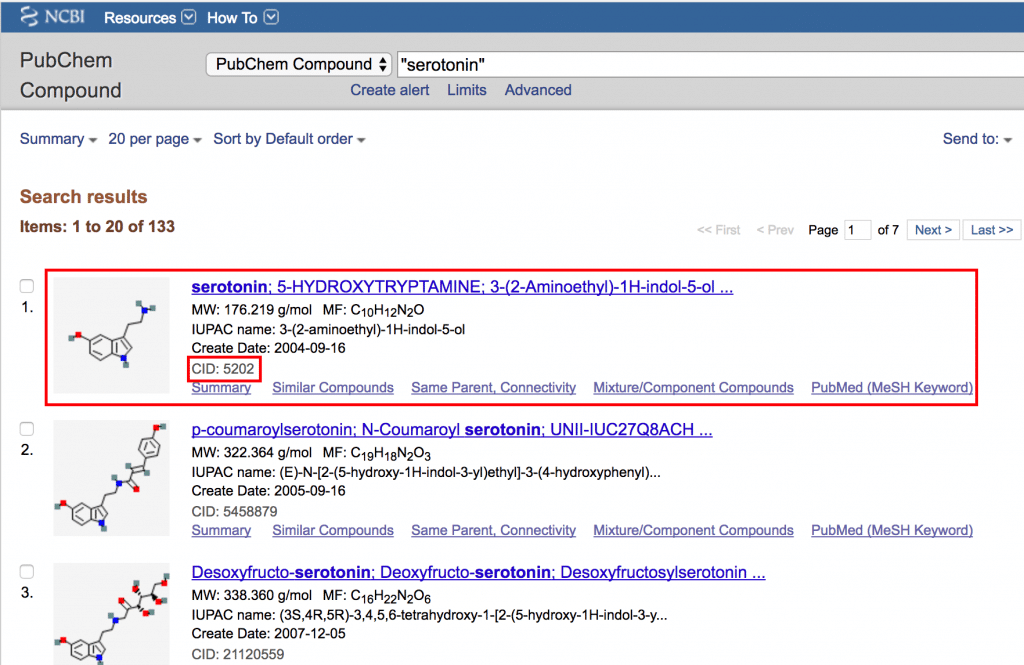
CID指定で検索、ダウンロードできるPubChem Download Serviceに移動します。
IDを入力、ファイル形式をXMLにしてダウンロードします。
ちょっと待ってると自動でダウンロードが開始します。
適当なエディタで開きます。
sertoninで検索。ヒットせず。
名前が取れないと辞書が作れない。Compoundは構造の記述だけみたいです。
化合物の名前とかは載っていない。
Substanceで検索
改めてSubstanceの方で検索。

SIDをメモります(SID = 111677885)。
PubChem Download Serviceに移動します。
データベースはSubstanceを選択、IDにSIDを入力します。ふぉーまっとはXMLにしてダウンロードしてみます。
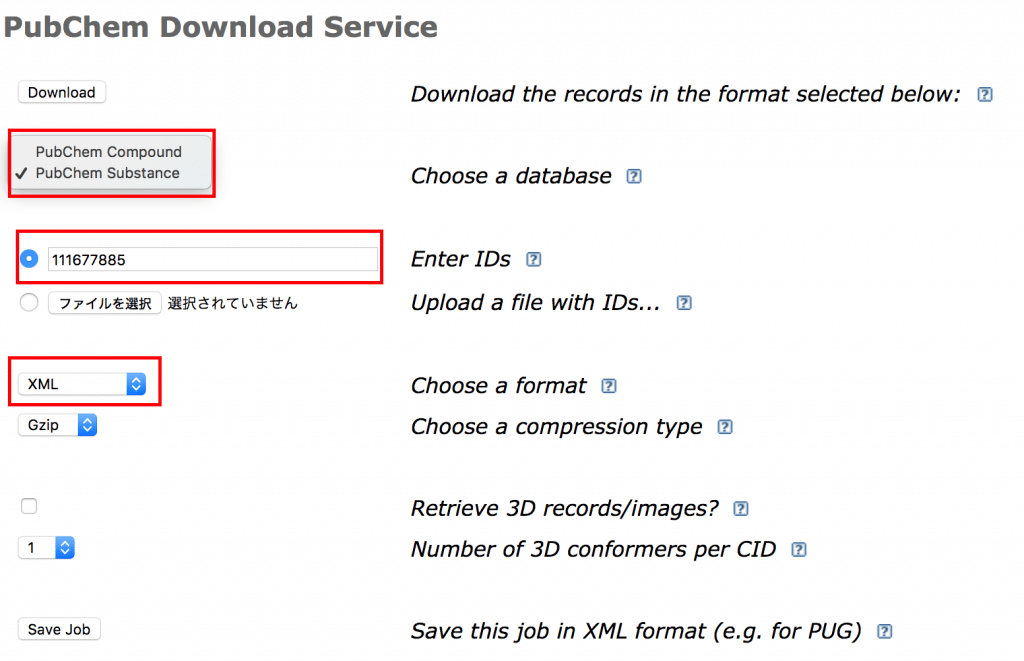
synonyms(同義語)のとこに名称がたくさんありました。
セロトニン別名多いなぁ。
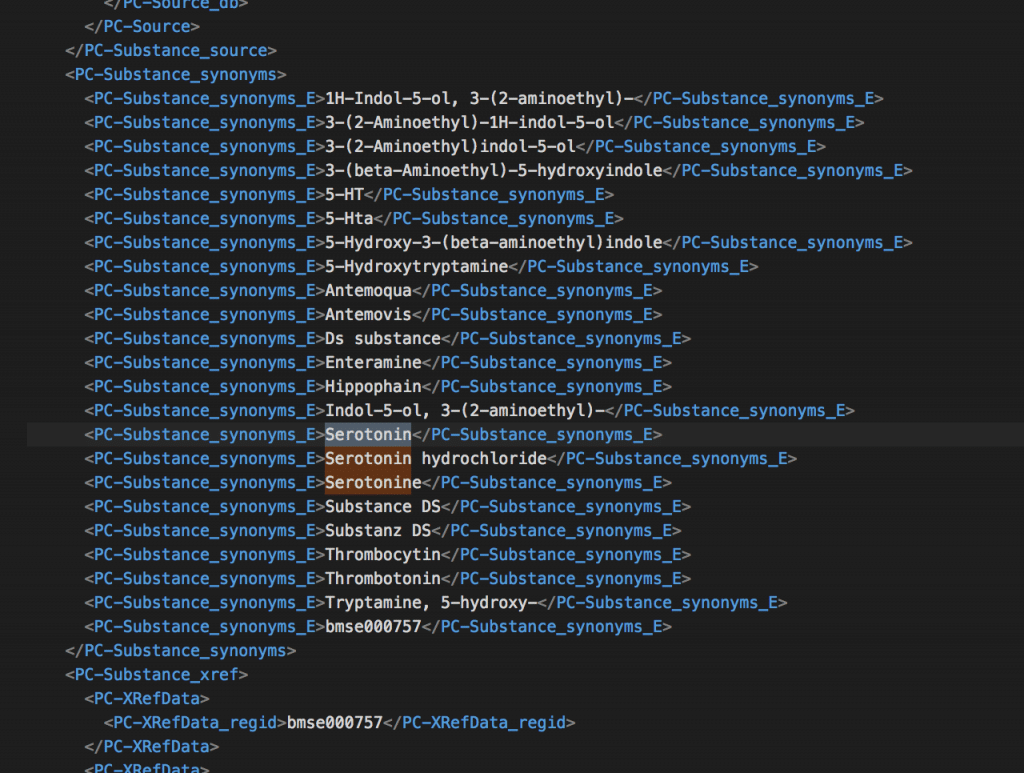
ともあれ、XMLで化合物名を取得できることがわかりました。
ダウンロード
もっとも今回はサイト上での利用方法には関心がなくて、もっぱら機械的に処理するためのデータが欲しいわけですが。
さすがイケてます。ちゃんとデータをダウンロードする手引きがありました。
まとめてダウンロードするにはFTPサイトを利用するのが良いみたいです。
FTPサイトにアクセスすると以下のようなディレクトリ構造が表示されます。
Substance/へ移動します。毎日、毎週、毎月の更新分がそれぞれDaily/、Weekly、Monthlyに保存されているというようなことがドキュメントに書いてありました。

とりあえずDaily/の中に入ってさらに日付ディレクトリを選択します。

SDF/にはSDFファイルが入っています。
SDFは化合物を行列形式で表記したものです。
詳しくは以下のサイトを参考にしてください。
(構造式って機械に理解しにくいし、一意じゃないよね、新しい表記方法考えようぜ!って以前友人と盛り上がったら既にありました。無知の極み)
今回はXML形式のものをダウンロードします。
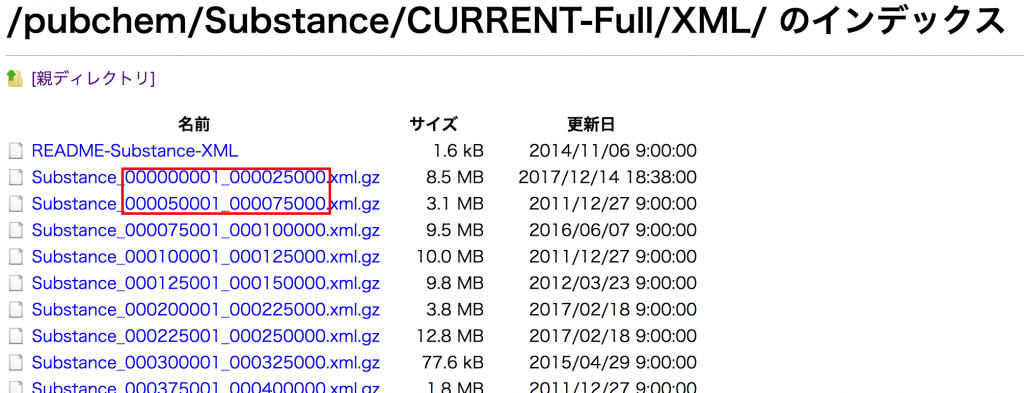
XML/に移動して、圧縮されたgzipファイルをダウンロード、手元で解凍します。

READMEを読むと、ファイル名の数字がそのファイルに含まれるSubstanceのSIDの範囲とのことです。
これだと、SID 348350001〜348375000までの化合物が含まれているってはずなんですが、
実際にはSID 348356513〜348356522の10件だけでした。
同名のDailyのファイルを統合するんでしょうかね。
大本命の全リストはCURRENT-Full/に入っています。
んー。3億5000万のSubstanceがあるらしい。大変だ。
ちょいちょい抜けてるのが気になりますが。
これで辞書つくってみます。
全部synonymsで同列に扱わずに代表名みたいなのがあると良かったですね。1つの化合物に別名が5つあるとしたら20億弱のデータになります。
パフォーマンスがどうなるか気になるが。とりあえずやってみる、ですね。
参考
- PubChemを利用して化学物質やアッセイの結果を調べる 統合TV(togotv)|生命科学系DB・ツール使い倒し系チャンネル
- PubChemを利用して化学物質やアッセイの結果を調べる 2017 統合TV(togotv)|生命科学系DB・ツール使い倒し系チャンネル
- PubChemの有用性③ 活性情報 PubChem BioAssayの特徴と創薬情報としての有用性
- 放牧33日目-「Pubchemの使い方を学ぶ」 – DBCLSお荷物研究員Go_with_twillの日記
- 2. SDFファイルをどうやって手に入れるか – ESI友の会:メタボロミクスの発展を目指して
- Downloading PubChem Data | PubChem Docs